Machine learning algorithms have hyperparameters that allow you to tailor the behavior of the algorithm to your specific dataset.
Hyperparameters are different from parameters, which are the internal coefficients or weights for a model found by the learning algorithm. Unlike parameters, hyperparameters are specified by the practitioner when configuring the model.
Typically, it is challenging to know what values to use for the hyperparameters of a given algorithm on a given dataset, therefore it is common to use random or grid search strategies for different hyperparameter values.
The more hyperparameters of an algorithm that you need to tune, the slower the tuning process. Therefore, it is desirable to select a minimum subset of model hyperparameters to search or tune.
Not all model hyperparameters are equally important. Some hyperparameters have an outsized effect on the behavior, and in turn, the performance of a machine learning algorithm.
As a machine learning practitioner, you must know which hyperparameters to focus on to get a good result quickly.
In this tutorial, you will discover those hyperparameters that are most important for some of the top machine learning algorithms.
Let’s get started.
- Update Jan/2020: Updated for changes in scikit-learn v0.22 API.

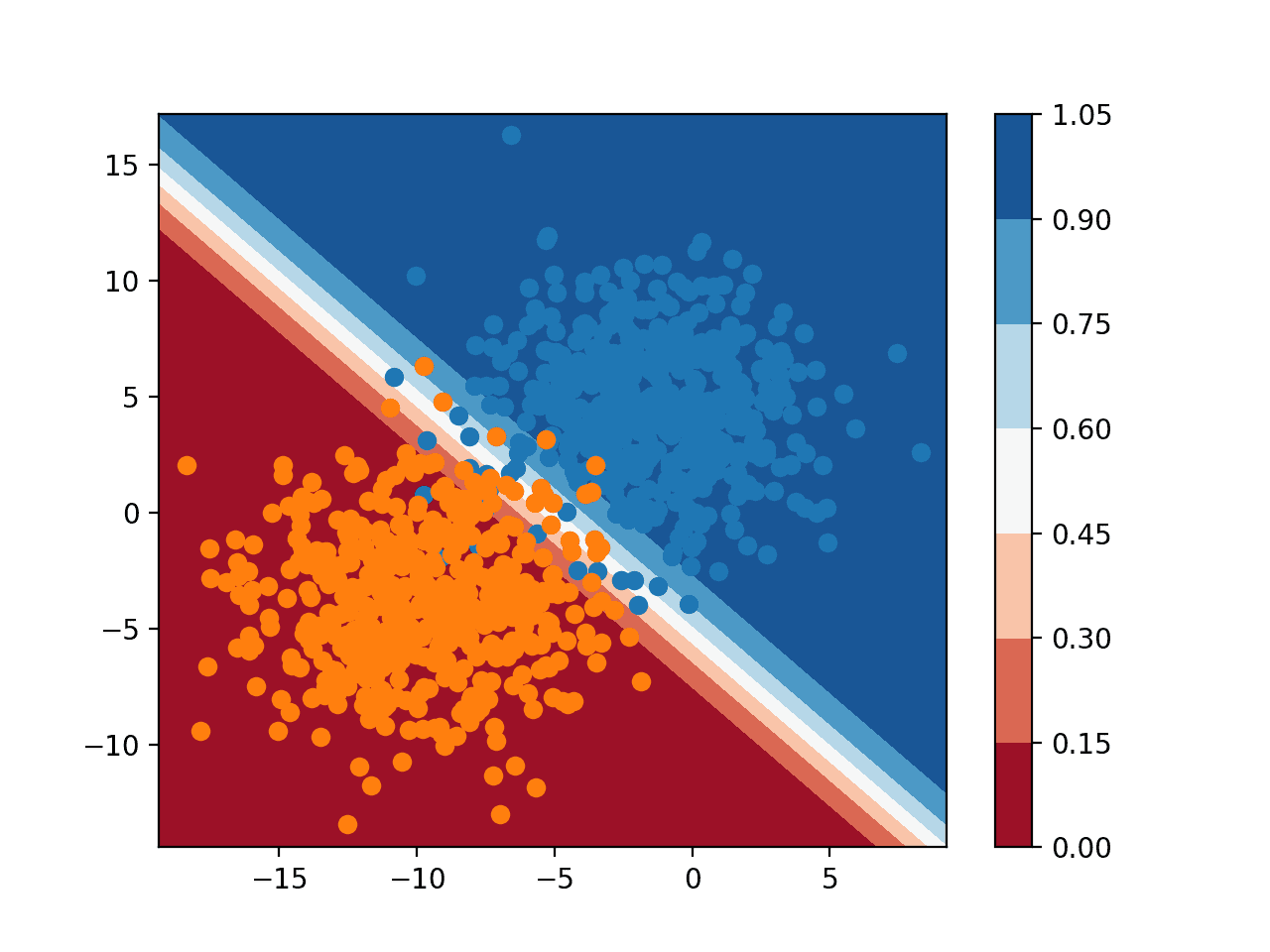
Hyperparameters for Classification Machine Learning Algorithms
Photo by shuttermonkey, some rights reserved.
Classification Algorithms Overview
We will take a closer look at the important hyperparameters of the top machine learning algorithms that you may use for classification.
We will look at the hyperparameters you need to focus on and suggested values to try when tuning the model on your dataset.
The suggestions are based both on advice from textbooks on the algorithms and practical advice suggested by practitioners, as well as a little of my own experience.
The seven classification algorithms we will look at are as follows:
- Logistic Regression
- Ridge Classifier
- K-Nearest Neighbors (KNN)
- Support Vector Machine (SVM)
- Bagged Decision Trees (Bagging)
- Random Forest
- Stochastic Gradient Boosting
We will consider these algorithms in the context of their scikit-learn implementation (Python); nevertheless, you can use the same hyperparameter suggestions with other platforms, such as Weka and R.
A small grid searching example is also given for each algorithm that you can use as a starting point for your own classification predictive modeling project.
Note: if you have had success with different hyperparameter values or even different hyperparameters than those suggested in this tutorial, let me know in the comments below. I’d love to hear about it.
Let’s dive in.
Logistic Regression
Logistic regression does not really have any critical hyperparameters to tune.
Sometimes, you can see useful differences in performance or convergence with different solvers (solver).
- solver in [‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’]
Regularization (penalty) can sometimes be helpful.
- penalty in [‘none’, ‘l1’, ‘l2’, ‘elasticnet’]
Note: not all solvers support all regularization terms.
The C parameter controls the penality strength, which can also be effective.
- C in [100, 10, 1.0, 0.1, 0.01]
For the full list of hyperparameters, see:
The example below demonstrates grid searching the key hyperparameters for LogisticRegression on a synthetic binary classification dataset.
Some combinations were omitted to cut back on the warnings/errors.
# example of grid searching key hyperparametres for logistic regression
from sklearn.datasets import make_blobs
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
# define dataset
X, y = make_blobs(n_samples=1000, centers=2, n_features=100, cluster_std=20)
# define models and parameters
model = LogisticRegression()
solvers = ['newton-cg', 'lbfgs', 'liblinear']
penalty = ['l2']
c_values = [100, 10, 1.0, 0.1, 0.01]
# define grid search
grid = dict(solver=solvers,penalty=penalty,C=c_values)
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
grid_search = GridSearchCV(estimator=model, param_grid=grid, n_jobs=-1, cv=cv, scoring='accuracy',error_score=0)
grid_result = grid_search.fit(X, y)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))Running the example prints the best result as well as the results from all combinations evaluated.
Best: 0.945333 using {'C': 0.01, 'penalty': 'l2', 'solver': 'liblinear'}
0.936333 (0.016829) with: {'C': 100, 'penalty': 'l2', 'solver': 'newton-cg'}
0.937667 (0.017259) with: {'C': 100, 'penalty': 'l2', 'solver': 'lbfgs'}
0.938667 (0.015861) with: {'C': 100, 'penalty': 'l2', 'solver': 'liblinear'}
0.936333 (0.017413) with: {'C': 10, 'penalty': 'l2', 'solver': 'newton-cg'}
0.938333 (0.017904) with: {'C': 10, 'penalty': 'l2', 'solver': 'lbfgs'}
0.939000 (0.016401) with: {'C': 10, 'penalty': 'l2', 'solver': 'liblinear'}
0.937333 (0.017114) with: {'C': 1.0, 'penalty': 'l2', 'solver': 'newton-cg'}
0.939000 (0.017195) with: {'C': 1.0, 'penalty': 'l2', 'solver': 'lbfgs'}
0.939000 (0.015780) with: {'C': 1.0, 'penalty': 'l2', 'solver': 'liblinear'}
0.940000 (0.015706) with: {'C': 0.1, 'penalty': 'l2', 'solver': 'newton-cg'}
0.940333 (0.014941) with: {'C': 0.1, 'penalty': 'l2', 'solver': 'lbfgs'}
0.941000 (0.017000) with: {'C': 0.1, 'penalty': 'l2', 'solver': 'liblinear'}
0.943000 (0.016763) with: {'C': 0.01, 'penalty': 'l2', 'solver': 'newton-cg'}
0.943000 (0.016763) with: {'C': 0.01, 'penalty': 'l2', 'solver': 'lbfgs'}
0.945333 (0.017651) with: {'C': 0.01, 'penalty': 'l2', 'solver': 'liblinear'}
Ridge Classifier
Ridge regression is a penalized linear regression model for predicting a numerical value.
Nevertheless, it can be very effective when applied to classification.
Perhaps the most important parameter to tune is the regularization strength (alpha). A good starting point might be values in the range [0.1 to 1.0]
- alpha in [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
For the full list of hyperparameters, see:
The example below demonstrates grid searching the key hyperparameters for RidgeClassifier on a synthetic binary classification dataset.
# example of grid searching key hyperparametres for ridge classifier
from sklearn.datasets import make_blobs
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import RidgeClassifier
# define dataset
X, y = make_blobs(n_samples=1000, centers=2, n_features=100, cluster_std=20)
# define models and parameters
model = RidgeClassifier()
alpha = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
# define grid search
grid = dict(alpha=alpha)
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
grid_search = GridSearchCV(estimator=model, param_grid=grid, n_jobs=-1, cv=cv, scoring='accuracy',error_score=0)
grid_result = grid_search.fit(X, y)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))Running the example prints the best result as well as the results from all combinations evaluated.
Best: 0.974667 using {'alpha': 0.1}
0.974667 (0.014545) with: {'alpha': 0.1}
0.974667 (0.014545) with: {'alpha': 0.2}
0.974667 (0.014545) with: {'alpha': 0.3}
0.974667 (0.014545) with: {'alpha': 0.4}
0.974667 (0.014545) with: {'alpha': 0.5}
0.974667 (0.014545) with: {'alpha': 0.6}
0.974667 (0.014545) with: {'alpha': 0.7}
0.974667 (0.014545) with: {'alpha': 0.8}
0.974667 (0.014545) with: {'alpha': 0.9}
0.974667 (0.014545) with: {'alpha': 1.0}
K-Nearest Neighbors (KNN)
The most important hyperparameter for KNN is the number of neighbors (n_neighbors).
Test values between at least 1 and 21, perhaps just the odd numbers.
- n_neighbors in [1 to 21]
It may also be interesting to test different distance metrics (metric) for choosing the composition of the neighborhood.
- metric in [‘euclidean’, ‘manhattan’, ‘minkowski’]
For a fuller list see:
It may also be interesting to test the contribution of members of the neighborhood via different weightings (weights).
- weights in [‘uniform’, ‘distance’]
For the full list of hyperparameters, see:
The example below demonstrates grid searching the key hyperparameters for KNeighborsClassifier on a synthetic binary classification dataset.
# example of grid searching key hyperparametres for KNeighborsClassifier
from sklearn.datasets import make_blobs
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
# define dataset
X, y = make_blobs(n_samples=1000, centers=2, n_features=100, cluster_std=20)
# define models and parameters
model = KNeighborsClassifier()
n_neighbors = range(1, 21, 2)
weights = ['uniform', 'distance']
metric = ['euclidean', 'manhattan', 'minkowski']
# define grid search
grid = dict(n_neighbors=n_neighbors,weights=weights,metric=metric)
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
grid_search = GridSearchCV(estimator=model, param_grid=grid, n_jobs=-1, cv=cv, scoring='accuracy',error_score=0)
grid_result = grid_search.fit(X, y)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))Running the example prints the best result as well as the results from all combinations evaluated.
Best: 0.937667 using {'metric': 'manhattan', 'n_neighbors': 13, 'weights': 'uniform'}
0.833667 (0.031674) with: {'metric': 'euclidean', 'n_neighbors': 1, 'weights': 'uniform'}
0.833667 (0.031674) with: {'metric': 'euclidean', 'n_neighbors': 1, 'weights': 'distance'}
0.895333 (0.030081) with: {'metric': 'euclidean', 'n_neighbors': 3, 'weights': 'uniform'}
0.895333 (0.030081) with: {'metric': 'euclidean', 'n_neighbors': 3, 'weights': 'distance'}
0.909000 (0.021810) with: {'metric': 'euclidean', 'n_neighbors': 5, 'weights': 'uniform'}
0.909000 (0.021810) with: {'metric': 'euclidean', 'n_neighbors': 5, 'weights': 'distance'}
0.925333 (0.020774) with: {'metric': 'euclidean', 'n_neighbors': 7, 'weights': 'uniform'}
0.925333 (0.020774) with: {'metric': 'euclidean', 'n_neighbors': 7, 'weights': 'distance'}
0.929000 (0.027368) with: {'metric': 'euclidean', 'n_neighbors': 9, 'weights': 'uniform'}
0.929000 (0.027368) with: {'metric': 'euclidean', 'n_neighbors': 9, 'weights': 'distance'}
...
Support Vector Machine (SVM)
The SVM algorithm, like gradient boosting, is very popular, very effective, and provides a large number of hyperparameters to tune.
Perhaps the first important parameter is the choice of kernel that will control the manner in which the input variables will be projected. There are many to choose from, but linear, polynomial, and RBF are the most common, perhaps just linear and RBF in practice.
- kernels in [‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’]
If the polynomial kernel works out, then it is a good idea to dive into the degree hyperparameter.
Another critical parameter is the penalty (C) that can take on a range of values and has a dramatic effect on the shape of the resulting regions for each class. A log scale might be a good starting point.
- C in [100, 10, 1.0, 0.1, 0.001]
For the full list of hyperparameters, see:
The example below demonstrates grid searching the key hyperparameters for SVC on a synthetic binary classification dataset.
# example of grid searching key hyperparametres for SVC
from sklearn.datasets import make_blobs
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
# define dataset
X, y = make_blobs(n_samples=1000, centers=2, n_features=100, cluster_std=20)
# define model and parameters
model = SVC()
kernel = ['poly', 'rbf', 'sigmoid']
C = [50, 10, 1.0, 0.1, 0.01]
gamma = ['scale']
# define grid search
grid = dict(kernel=kernel,C=C,gamma=gamma)
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
grid_search = GridSearchCV(estimator=model, param_grid=grid, n_jobs=-1, cv=cv, scoring='accuracy',error_score=0)
grid_result = grid_search.fit(X, y)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))Running the example prints the best result as well as the results from all combinations evaluated.
Best: 0.974333 using {'C': 1.0, 'gamma': 'scale', 'kernel': 'poly'}
0.973667 (0.012512) with: {'C': 50, 'gamma': 'scale', 'kernel': 'poly'}
0.970667 (0.018062) with: {'C': 50, 'gamma': 'scale', 'kernel': 'rbf'}
0.945333 (0.024594) with: {'C': 50, 'gamma': 'scale', 'kernel': 'sigmoid'}
0.973667 (0.012512) with: {'C': 10, 'gamma': 'scale', 'kernel': 'poly'}
0.970667 (0.018062) with: {'C': 10, 'gamma': 'scale', 'kernel': 'rbf'}
0.957000 (0.016763) with: {'C': 10, 'gamma': 'scale', 'kernel': 'sigmoid'}
0.974333 (0.012565) with: {'C': 1.0, 'gamma': 'scale', 'kernel': 'poly'}
0.971667 (0.016948) with: {'C': 1.0, 'gamma': 'scale', 'kernel': 'rbf'}
0.966333 (0.016224) with: {'C': 1.0, 'gamma': 'scale', 'kernel': 'sigmoid'}
0.972333 (0.013585) with: {'C': 0.1, 'gamma': 'scale', 'kernel': 'poly'}
0.974000 (0.013317) with: {'C': 0.1, 'gamma': 'scale', 'kernel': 'rbf'}
0.971667 (0.015934) with: {'C': 0.1, 'gamma': 'scale', 'kernel': 'sigmoid'}
0.972333 (0.013585) with: {'C': 0.01, 'gamma': 'scale', 'kernel': 'poly'}
0.973667 (0.014716) with: {'C': 0.01, 'gamma': 'scale', 'kernel': 'rbf'}
0.974333 (0.013828) with: {'C': 0.01, 'gamma': 'scale', 'kernel': 'sigmoid'}
Bagged Decision Trees (Bagging)
The most important parameter for bagged decision trees is the number of trees (n_estimators).
Ideally, this should be increased until no further improvement is seen in the model.
Good values might be a log scale from 10 to 1,000.
- n_estimators in [10, 100, 1000]
For the full list of hyperparameters, see:
The example below demonstrates grid searching the key hyperparameters for BaggingClassifier on a synthetic binary classification dataset.
# example of grid searching key hyperparameters for BaggingClassifier
from sklearn.datasets import make_blobs
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import BaggingClassifier
# define dataset
X, y = make_blobs(n_samples=1000, centers=2, n_features=100, cluster_std=20)
# define models and parameters
model = BaggingClassifier()
n_estimators = [10, 100, 1000]
# define grid search
grid = dict(n_estimators=n_estimators)
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
grid_search = GridSearchCV(estimator=model, param_grid=grid, n_jobs=-1, cv=cv, scoring='accuracy',error_score=0)
grid_result = grid_search.fit(X, y)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))Running the example prints the best result as well as the results from all combinations evaluated.
Best: 0.873667 using {'n_estimators': 1000}
0.839000 (0.038588) with: {'n_estimators': 10}
0.869333 (0.030434) with: {'n_estimators': 100}
0.873667 (0.035070) with: {'n_estimators': 1000}
Random Forest
The most important parameter is the number of random features to sample at each split point (max_features).
You could try a range of integer values, such as 1 to 20, or 1 to half the number of input features.
- max_features [1 to 20]
Alternately, you could try a suite of different default value calculators.
- max_features in [‘sqrt’, ‘log2’]
Another important parameter for random forest is the number of trees (n_estimators).
Ideally, this should be increased until no further improvement is seen in the model.
Good values might be a log scale from 10 to 1,000.
- n_estimators in [10, 100, 1000]
For the full list of hyperparameters, see:
The example below demonstrates grid searching the key hyperparameters for BaggingClassifier on a synthetic binary classification dataset.
# example of grid searching key hyperparameters for RandomForestClassifier
from sklearn.datasets import make_blobs
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# define dataset
X, y = make_blobs(n_samples=1000, centers=2, n_features=100, cluster_std=20)
# define models and parameters
model = RandomForestClassifier()
n_estimators = [10, 100, 1000]
max_features = ['sqrt', 'log2']
# define grid search
grid = dict(n_estimators=n_estimators,max_features=max_features)
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
grid_search = GridSearchCV(estimator=model, param_grid=grid, n_jobs=-1, cv=cv, scoring='accuracy',error_score=0)
grid_result = grid_search.fit(X, y)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))Running the example prints the best result as well as the results from all combinations evaluated.
Best: 0.952000 using {'max_features': 'log2', 'n_estimators': 1000}
0.841000 (0.032078) with: {'max_features': 'sqrt', 'n_estimators': 10}
0.938333 (0.020830) with: {'max_features': 'sqrt', 'n_estimators': 100}
0.944667 (0.024998) with: {'max_features': 'sqrt', 'n_estimators': 1000}
0.817667 (0.033235) with: {'max_features': 'log2', 'n_estimators': 10}
0.940667 (0.021592) with: {'max_features': 'log2', 'n_estimators': 100}
0.952000 (0.019562) with: {'max_features': 'log2', 'n_estimators': 1000}
Stochastic Gradient Boosting
Also called Gradient Boosting Machine (GBM) or named for the specific implementation, such as XGBoost.
The gradient boosting algorithm has many parameters to tune.
There are some parameter pairings that are important to consider. The first is the learning rate, also called shrinkage or eta (learning_rate) and the number of trees in the model (n_estimators). Both could be considered on a log scale, although in different directions.
- learning_rate in [0.001, 0.01, 0.1]
- n_estimators [10, 100, 1000]
Another pairing is the number of rows or subset of the data to consider for each tree (subsample) and the depth of each tree (max_depth). These could be grid searched at a 0.1 and 1 interval respectively, although common values can be tested directly.
- subsample in [0.5, 0.7, 1.0]
- max_depth in [3, 7, 9]
For more detailed advice on tuning the XGBoost implementation, see:
For the full list of hyperparameters, see:
The example below demonstrates grid searching the key hyperparameters for GradientBoostingClassifier on a synthetic binary classification dataset.
# example of grid searching key hyperparameters for GradientBoostingClassifier
from sklearn.datasets import make_blobs
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import GradientBoostingClassifier
# define dataset
X, y = make_blobs(n_samples=1000, centers=2, n_features=100, cluster_std=20)
# define models and parameters
model = GradientBoostingClassifier()
n_estimators = [10, 100, 1000]
learning_rate = [0.001, 0.01, 0.1]
subsample = [0.5, 0.7, 1.0]
max_depth = [3, 7, 9]
# define grid search
grid = dict(learning_rate=learning_rate, n_estimators=n_estimators, subsample=subsample, max_depth=max_depth)
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
grid_search = GridSearchCV(estimator=model, param_grid=grid, n_jobs=-1, cv=cv, scoring='accuracy',error_score=0)
grid_result = grid_search.fit(X, y)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))Running the example prints the best result as well as the results from all combinations evaluated.
Best: 0.936667 using {'learning_rate': 0.01, 'max_depth': 3, 'n_estimators': 1000, 'subsample': 0.5}
0.803333 (0.042058) with: {'learning_rate': 0.001, 'max_depth': 3, 'n_estimators': 10, 'subsample': 0.5}
0.783667 (0.042386) with: {'learning_rate': 0.001, 'max_depth': 3, 'n_estimators': 10, 'subsample': 0.7}
0.711667 (0.041157) with: {'learning_rate': 0.001, 'max_depth': 3, 'n_estimators': 10, 'subsample': 1.0}
0.832667 (0.040244) with: {'learning_rate': 0.001, 'max_depth': 3, 'n_estimators': 100, 'subsample': 0.5}
0.809667 (0.040040) with: {'learning_rate': 0.001, 'max_depth': 3, 'n_estimators': 100, 'subsample': 0.7}
0.741333 (0.043261) with: {'learning_rate': 0.001, 'max_depth': 3, 'n_estimators': 100, 'subsample': 1.0}
0.881333 (0.034130) with: {'learning_rate': 0.001, 'max_depth': 3, 'n_estimators': 1000, 'subsample': 0.5}
0.866667 (0.035150) with: {'learning_rate': 0.001, 'max_depth': 3, 'n_estimators': 1000, 'subsample': 0.7}
0.838333 (0.037424) with: {'learning_rate': 0.001, 'max_depth': 3, 'n_estimators': 1000, 'subsample': 1.0}
0.838333 (0.036614) with: {'learning_rate': 0.001, 'max_depth': 7, 'n_estimators': 10, 'subsample': 0.5}
0.821667 (0.040586) with: {'learning_rate': 0.001, 'max_depth': 7, 'n_estimators': 10, 'subsample': 0.7}
0.729000 (0.035903) with: {'learning_rate': 0.001, 'max_depth': 7, 'n_estimators': 10, 'subsample': 1.0}
0.884667 (0.036854) with: {'learning_rate': 0.001, 'max_depth': 7, 'n_estimators': 100, 'subsample': 0.5}
0.871333 (0.035094) with: {'learning_rate': 0.001, 'max_depth': 7, 'n_estimators': 100, 'subsample': 0.7}
0.729000 (0.037625) with: {'learning_rate': 0.001, 'max_depth': 7, 'n_estimators': 100, 'subsample': 1.0}
0.905667 (0.033134) with: {'learning_rate': 0.001, 'max_depth': 7, 'n_estimators': 1000, 'subsample': 0.5}
...
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Summary
In this tutorial, you discovered the top hyperparameters and how to configure them for top machine learning algorithms.
Do you have other hyperparameter suggestions? Let me know in the comments below.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post Tune Hyperparameters for Classification Machine Learning Algorithms appeared first on Machine Learning Mastery.