Radius Neighbors Classifier is a classification machine learning algorithm.
It is an extension to the k-nearest neighbors algorithm that makes predictions using all examples in the radius of a new example rather than the k-closest neighbors.
As such, the radius-based approach to selecting neighbors is more appropriate for sparse data, preventing examples that are far away in the feature space from contributing to a prediction.
In this tutorial, you will discover the Radius Neighbors Classifier classification machine learning algorithm.
After completing this tutorial, you will know:
- The Nearest Radius Neighbors Classifier is a simple extension of the k-nearest neighbors classification algorithm.
- How to fit, evaluate, and make predictions with the Radius Neighbors Classifier model with Scikit-Learn.
- How to tune the hyperparameters of the Radius Neighbors Classifier algorithm on a given dataset.
Let’s get started.

Radius Neighbors Classifier Algorithm With Python
Photo by J. Triepke, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
- Radius Neighbors Classifier
- Radius Neighbors Classifier With Scikit-Learn
- Tune Radius Neighbors Classifier Hyperparameters
Radius Neighbors Classifier
Radius Neighbors is a classification machine learning algorithm.
It is based on the k-nearest neighbors algorithm, or kNN. kNN involves taking the entire training dataset and storing it. Then, at prediction time, the k-closest examples in the training dataset are located for each new example for which we want to predict. The mode (most common value) class label from the k neighbors is then assigned to the new example.
For more on the k-nearest neighbours algorithm, see the tutorial:
The Radius Neighbors Classifier is similar in that training involves storing the entire training dataset. The way that the training dataset is used during prediction is different.
Instead of locating the k-neighbors, the Radius Neighbors Classifier locates all examples in the training dataset that are within a given radius of the new example. The radius neighbors are then used to make a prediction for the new example.
The radius is defined in the feature space and generally assumes that the input variables are numeric and scaled to the range 0-1, e.g. normalized.
The radius-based approach to locating neighbors is appropriate for those datasets where it is desirable for the contribution of neighbors to be proportional to the density of examples in the feature space.
Given a fixed radius, dense regions of the feature space will contribute more information and sparse regions will contribute less information. It is this latter case that is most desirable and it prevents examples very far in feature space from the new example from contributing to the prediction.
As such, the Radius Neighbors Classifier may be more appropriate for prediction problems where there are sparse regions of the feature space.
Given that the radius is fixed in all dimensions of the feature space, it will become less effective as the number of input features is increased, which causes examples in the feature space to spread further and further apart. This property is referred to as the curse of dimensionality.
Radius Neighbors Classifier With Scikit-Learn
The Radius Neighbors Classifier is available in the scikit-learn Python machine learning library via the RadiusNeighborsClassifier class.
The class allows you to specify the size of the radius used when making a prediction via the “radius” argument, which defaults to 1.0.
... # create the model model = RadiusNeighborsClassifier(radius=1.0)
Another important hyperparameter is the “weights” argument that controls whether neighbors contribute to the prediction in a ‘uniform‘ manner or inverse to the distance (‘distance‘) from the example. Uniform weight is used by default.
... # create the model model = RadiusNeighborsClassifier(weights='uniform')
We can demonstrate the Radius Neighbors Classifier with a worked example.
First, let’s define a synthetic classification dataset.
We will use the make_classification() function to create a dataset with 1,000 examples, each with 20 input variables.
The example below creates and summarizes the dataset.
# test classification dataset from sklearn.datasets import make_classification # define dataset X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1) # summarize the dataset print(X.shape, y.shape)
Running the example creates the dataset and confirms the number of rows and columns of the dataset.
(1000, 20) (1000,)
We can fit and evaluate a Radius Neighbors Classifier model using repeated stratified k-fold cross-validation via the RepeatedStratifiedKFold class. We will use 10 folds and three repeats in the test harness.
We will use the default configuration.
... # create the model model = RadiusNeighborsClassifier()
It is important that the feature space is scaled prior to preparing and using the model.
We can achieve this by using the MinMaxScaler to normalize the input features and use a Pipeline to first apply the scaling, then use the model.
...
# define model
model = RadiusNeighborsClassifier()
# create pipeline
pipeline = Pipeline(steps=[('norm', MinMaxScaler()),('model',model)])The complete example of evaluating the Radius Neighbors Classifier model for the synthetic binary classification task is listed below.
# evaluate an radius neighbors classifier model on the dataset
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
from sklearn.neighbors import RadiusNeighborsClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1)
# define model
model = RadiusNeighborsClassifier()
# create pipeline
pipeline = Pipeline(steps=[('norm', MinMaxScaler()),('model',model)])
# define model evaluation method
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate model
scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# summarize result
print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))Running the example evaluates the Radius Neighbors Classifier algorithm on the synthetic dataset and reports the average accuracy across the three repeats of 10-fold cross-validation.
Your specific results may vary given the stochastic nature of the learning algorithm. Consider running the example a few times.
In this case, we can see that the model achieved a mean accuracy of about 75.4 percent.
Mean Accuracy: 0.754 (0.042)
We may decide to use the Radius Neighbors Classifier as our final model and make predictions on new data.
This can be achieved by fitting the model pipeline on all available data and calling the predict() function passing in a new row of data.
We can demonstrate this with a complete example listed below.
# make a prediction with a radius neighbors classifier model on the dataset
from sklearn.datasets import make_classification
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
from sklearn.neighbors import RadiusNeighborsClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1)
# define model
model = RadiusNeighborsClassifier()
# create pipeline
pipeline = Pipeline(steps=[('norm', MinMaxScaler()),('model',model)])
# fit model
pipeline.fit(X, y)
# define new data
row = [2.47475454,0.40165523,1.68081787,2.88940715,0.91704519,-3.07950644,4.39961206,0.72464273,-4.86563631,-6.06338084,-1.22209949,-0.4699618,1.01222748,-0.6899355,-0.53000581,6.86966784,-3.27211075,-6.59044146,-2.21290585,-3.139579]
# make a prediction
yhat = pipeline.predict([row])
# summarize prediction
print('Predicted Class: %d' % yhat)Running the example fits the model and makes a class label prediction for a new row of data.
Predicted Class: 0
Next, we can look at configuring the model hyperparameters.
Tune Radius Neighbors Classifier Hyperparameters
The hyperparameters for the Radius Neighbors Classifier method must be configured for your specific dataset.
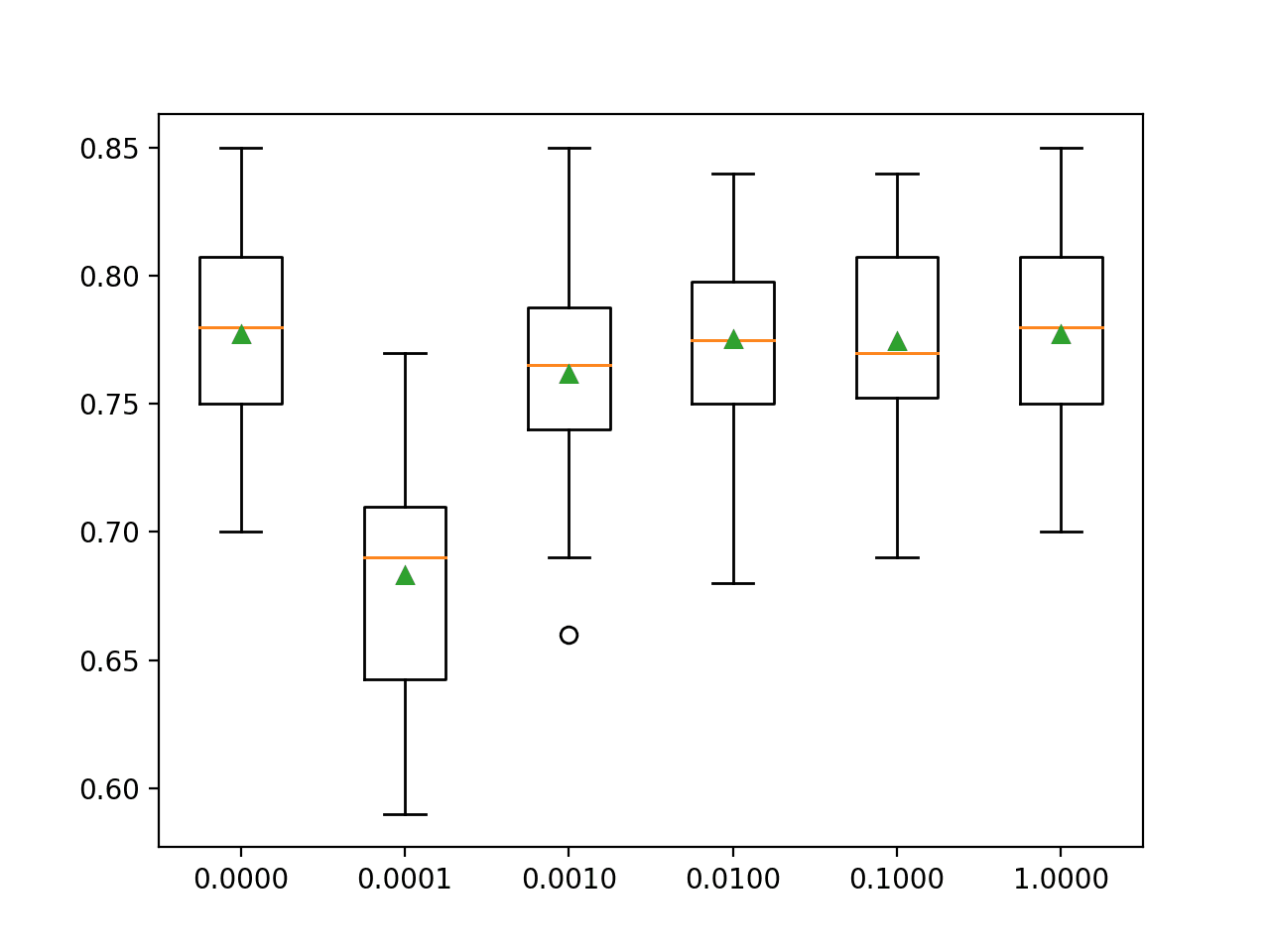
Perhaps the most important hyperparameter is the radius controlled via the “radius” argument. It is a good idea to test a range of values, perhaps around the value of 1.0.
We will explore values between 0.8 and 1.5 with a grid of 0.01 on our synthetic dataset.
... # define grid grid = dict() grid['model__radius'] = arange(0.8, 1.5, 0.01)
Note that we are grid searching the “radius” hyperparameter of the RadiusNeighborsClassifier within the Pipeline where the model is named “model” and, therefore, the radius parameter is accessed via model->radius with a double underscore (__) separator, e.g. “model__radius“.
The example below demonstrates this using the GridSearchCV class with a grid of values we have defined.
# grid search radius for radius neighbors classifier
from numpy import arange
from sklearn.datasets import make_classification
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
from sklearn.neighbors import RadiusNeighborsClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1)
# define model
model = RadiusNeighborsClassifier()
# create pipeline
pipeline = Pipeline(steps=[('norm', MinMaxScaler()),('model',model)])
# define model evaluation method
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# define grid
grid = dict()
grid['model__radius'] = arange(0.8, 1.5, 0.01)
# define search
search = GridSearchCV(pipeline, grid, scoring='accuracy', cv=cv, n_jobs=-1)
# perform the search
results = search.fit(X, y)
# summarize
print('Mean Accuracy: %.3f' % results.best_score_)
print('Config: %s' % results.best_params_)Running the example will evaluate each combination of configurations using repeated cross-validation.
Your specific results may vary given the stochastic nature of the learning algorithm. Try running the example a few times.
In this case, we can see that we achieved better results using a radius of 0.8 that gave an accuracy of about 87.2 percent compared to a radius of 1.0 in the previous example that gave an accuracy of about 75.4 percent.
Mean Accuracy: 0.872
Config: {'model__radius': 0.8}Another key hyperparameter is the manner in which examples in the radius contribute to the prediction via the “weights” argument. This can be set to “uniform” (the default), “distance” for inverse distance, or a custom function.
We can test both of these built-in weightings and see which performs better with our radius of 0.8.
... # define grid grid = dict() grid['model__weights'] = ['uniform', 'distance']
The complete example is listed below.
# grid search weights for radius neighbors classifier
from sklearn.datasets import make_classification
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
from sklearn.neighbors import RadiusNeighborsClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1)
# define model
model = RadiusNeighborsClassifier(radius=0.8)
# create pipeline
pipeline = Pipeline(steps=[('norm', MinMaxScaler()),('model',model)])
# define model evaluation method
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# define grid
grid = dict()
grid['model__weights'] = ['uniform', 'distance']
# define search
search = GridSearchCV(pipeline, grid, scoring='accuracy', cv=cv, n_jobs=-1)
# perform the search
results = search.fit(X, y)
# summarize
print('Mean Accuracy: %.3f' % results.best_score_)
print('Config: %s' % results.best_params_)Running the example fits the model and discovers the hyperparameters that give the best results using cross-validation.
Your specific results may vary given the stochastic nature of the learning algorithm. Try running the example a few times.
In this case, we can see an additional lift in mean classification accuracy from about 87.2 percent with ‘uniform‘ weights in the previous example to about 89.3 percent with ‘distance‘ weights in this case.
Mean Accuracy: 0.893
Config: {'model__weights': 'distance'}Another metric that you might wish to explore is the distance metric used via the ‘metric‘ argument that defaults to ‘minkowski‘.
It might be interesting to compare results to ‘euclidean‘ distance and perhaps ‘cityblock‘.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Tutorials
Books
- Applied Predictive Modeling, 2013.
- An Introduction to Statistical Learning with Applications in R, 2014.
APIs
- Nearest Neighbors, Scikit-Learn User Guide.
- sklearn.neighbors.RadiusNeighborsClassifier API.
- sklearn.pipeline.Pipeline API.
- sklearn.preprocessing.MinMaxScaler API.
Articles
Summary
In this tutorial, you discovered the Radius Neighbors Classifier classification machine learning algorithm.
Specifically, you learned:
- The Nearest Radius Neighbors Classifier is a simple extension of the k-nearest neighbors classification algorithm.
- How to fit, evaluate, and make predictions with the Radius Neighbors Classifier model with Scikit-Learn.
- How to tune the hyperparameters of the Radius Neighbors Classifier algorithm on a given dataset.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post Radius Neighbors Classifier Algorithm With Python appeared first on Machine Learning Mastery.